Jovialis
Advisor
- Messages
- 9,888
- Reaction score
- 6,794
- Points
- 113
- Ethnic group
- Italian
- Y-DNA haplogroup
- R1b-PF7566>Y227216
- mtDNA haplogroup
- H6a1b7
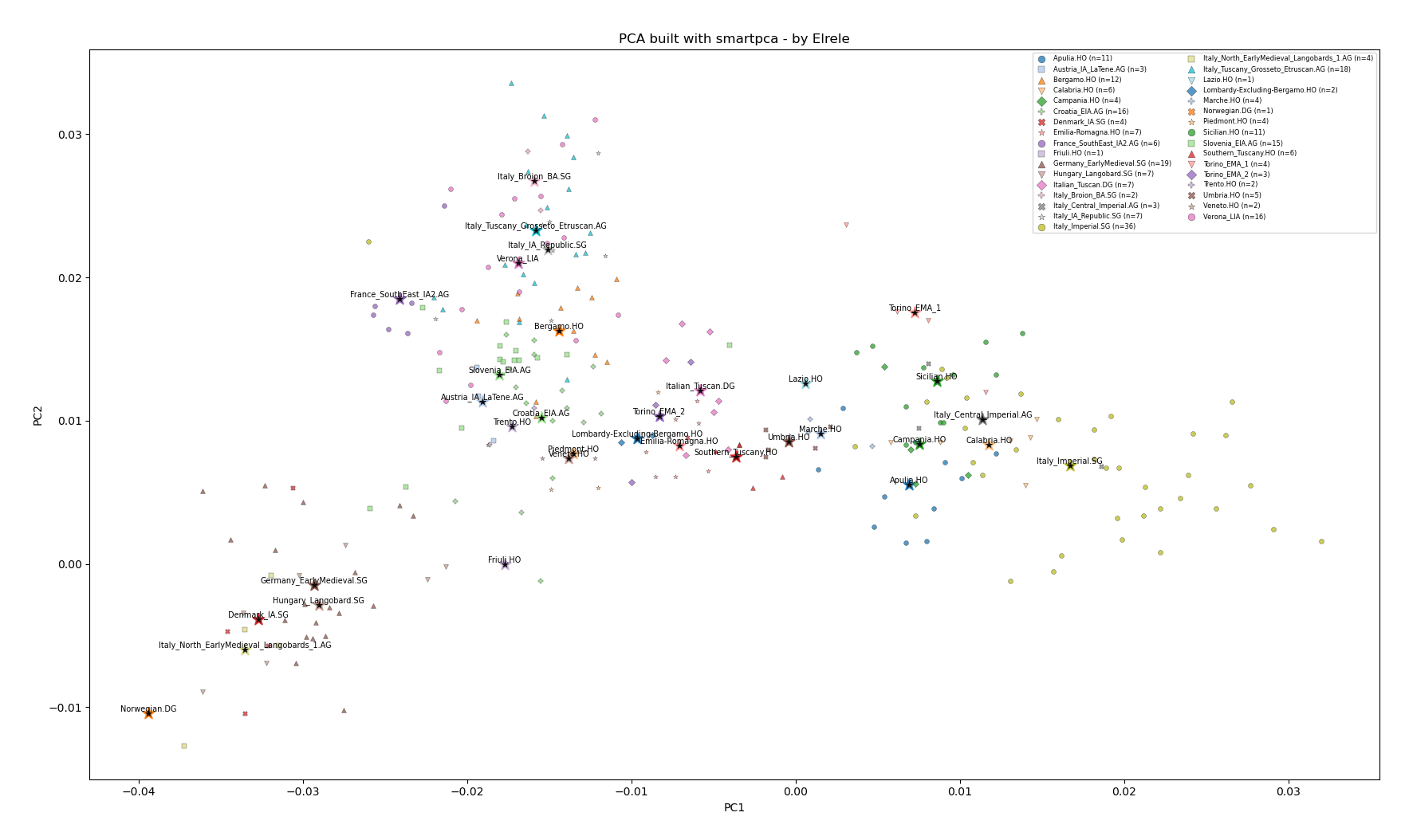
Comparison of Genetic Distances of C6 Central Mediterranean and Latini vs Moderns. By FST point estimates, nearly all tested modern populations are closer to C6 than to Latini, including Northern Italians. The two runs retained slightly different SNP sets (~460k vs ~534k after filtering), but this difference should have minimal practical impact on the overall pattern; it mainly affects only borderline cases, where the distances are extremely close.
FST runs with Admixtools2 the graphics were made in Rstudio
Latini in this run are R851, R1016, and R1021 which are the actual specific Latini listed in Antonio et al. 2019.


FST runs with Admixtools2 the graphics were made in Rstudio
Latini in this run are R851, R1016, and R1021 which are the actual specific Latini listed in Antonio et al. 2019.